





本站消息,截至2025年4月24日收盘股票配资app下载,润建股份(002929)报收于46.25元,下跌7.31%,换手率8.57%,成交量18.04万手,成....
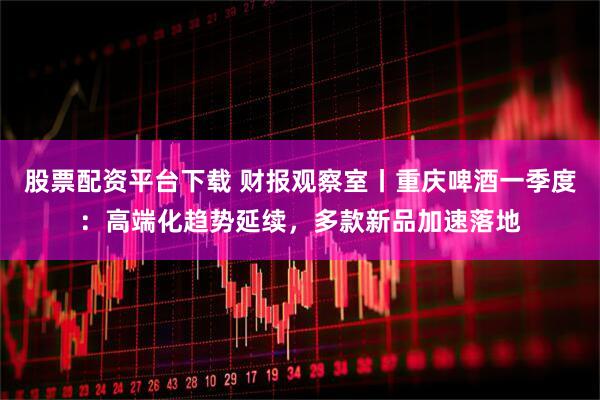
股票配资app下载 04-25中证智能财讯东山精密(002384)4月25日披露2024年年度报告。2024年,公司实现营业总收入367.70亿元,同比增长9.27%;归母净利润10.86亿....
炒股配资官方网平台 04-25中证智能财讯正邦科技(002157)4月25日披露2024年年度报告。2024年,公司实现营业总收入88.70亿元,同比增长26.86%;归母净利润2.16亿元....
在线股票配资官网 04-26近年来,从密集布局到技术扎根,中国车企正加速“抢滩”欧洲研发。2026年以来,吉利、奇瑞、零跑、小米等纷纷在欧洲核心城市设立研发机构,构建覆盖西欧、南欧、北欧的....

IT之家 5 月 28 日消息,北京时间今晚,小米 17T 和 17T Pro 手机正式发布,两款新机定位为 17 系列旗舰的更低价版本。按照 T 系列一贯思路....

meta公司近日在科技领域动作频频,引发市场广泛关注。据美国消费者新闻与商业频道(CNBC)报道,该公司于当地时间周三宣布,正式推出面向消费者的meta AI聊....

中国经济网北京5月15日讯 市场早盘探底回升,午后再度回落,三大指数集体收跌。截至收盘,上证指数报4135.39点,跌幅1.02%,成交额15192.40亿元;....

本月,多氟多新能源在2025年业绩说明会暨2026年投资者交流会上,公布了亮眼成绩单:全年营收达94.34亿元,归母净利润同比强劲增长168.97%,新能源电池....

来源:金十数据 中东战争引发的美国通胀“高烧不退”,正让黄金多头们倍感煎熬。在强美元和高收益率的夹击下,金价未来的路究竟在何方? 美国通胀数据持续升温引发市场对....

4月29日,重庆啤酒股份有限公司(简称“重庆啤酒”)发布2026年第一季度报告显示,重庆啤酒持续推进产品创新、产能布局与运营效率提升,延续了稳健发展态势,实现全....
【大河财立方 记者 吴春波】4月30日,由北京大学材料科学与工程学院、国际合作部留学生办公室、创新创业学院、校友工作办公室配资平台查询首推加杠网,北京大学深圳研....

智通财经APP获悉,据港交所2026年4月30日披露,安徽华恒生物科技股份有限公司(简称:华恒生物(688639.SH))向港交所提交上市申请书配资平台,华泰国....

“亚洲股王”台积电业绩炸裂! 4月16日,台积电披露一季报业绩,全面超预期。数据显示,台积电一季度净利润5725亿元新台币(约1230亿元人民币),预估为542....

 易配牛牛文章加载中,请稍后...
易配牛牛文章加载中,请稍后...
近年来,从密集布局到技术扎根,中国车企正加速“抢滩”欧洲研发。2026年以来,吉利、奇瑞、零跑、小米等纷纷在欧洲核心城市设立研发机构,构建覆盖西欧、南欧、北欧的....
meta公司近日在科技领域动作频频,引发市场广泛关注。据美国消费者新闻与商业频道(CNBC)报道,该公司于当地时间周三宣布,正式推出面向消费者的meta AI聊....
IT之家 5 月 28 日消息,北京时间今晚,小米 17T 和 17T Pro 手机正式发布,两款新机定位为 17 系列旗舰的更低价版本。按照 T 系列一贯思路....
本月,多氟多新能源在2025年业绩说明会暨2026年投资者交流会上,公布了亮眼成绩单:全年营收达94.34亿元,归母净利润同比强劲增长168.97%,新能源电池....
来源:金十数据 中东战争引发的美国通胀“高烧不退”,正让黄金多头们倍感煎熬。在强美元和高收益率的夹击下,金价未来的路究竟在何方? 美国通胀数据持续升温引发市场对....
中国经济网北京5月15日讯 市场早盘探底回升,午后再度回落,三大指数集体收跌。截至收盘,上证指数报4135.39点,跌幅1.02%,成交额15192.40亿元;....
【大河财立方 记者 吴春波】4月30日,由北京大学材料科学与工程学院、国际合作部留学生办公室、创新创业学院、校友工作办公室配资平台查询首推加杠网,北京大学深圳研....
智通财经APP获悉,据港交所2026年4月30日披露,安徽华恒生物科技股份有限公司(简称:华恒生物(688639.SH))向港交所提交上市申请书配资平台,华泰国....
4月29日,重庆啤酒股份有限公司(简称“重庆啤酒”)发布2026年第一季度报告显示,重庆啤酒持续推进产品创新、产能布局与运营效率提升,延续了稳健发展态势,实现全....
4月16日消息,据“网信中国”官微,近期,国家网信办会同相关部门依法处置一批公开推荐个股、诱导加入群组荐股、兜售非法荐股软件的账号。 在通报的部分典型案例中,“....

本站消息,截至2025年4月24日收盘股票配资app下载,润建股份(002929)报收于46.25元,下跌7.31%,换手率8.57%,成交量18.04万手,成....

中证智能财讯东山精密(002384)4月25日披露2024年年度报告。2024年,公司实现营业总收入367.70亿元,同比增长9.27%;归母净利润10.86亿....
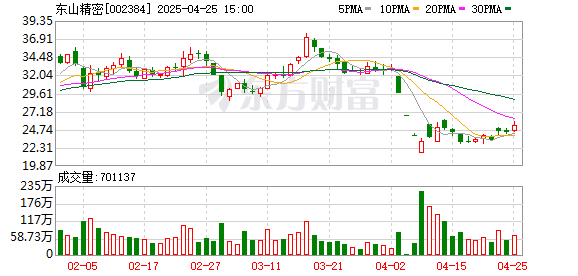
中证智能财讯正邦科技(002157)4月25日披露2024年年度报告。2024年,公司实现营业总收入88.70亿元,同比增长26.86%;归母净利润2.16亿元....
深交所将于5月19日至20日在深圳举办2025全球投资者大会 天津市人民政府网站公布《天津市促进人工智能创新发展行动方案(2025—2027年)》 5月16日,....

4月29日配资操盘股票,国家数据局局长刘烈宏在第八届数字中国建设峰会开幕式上表示,当前,加快推进数字中国建设,要紧紧抓住人工智能发展带来的前所未有的机遇,推动数....

彭博新闻社周五报道股票配资信息,丰田汽车公司董事长丰田章男提议以一项可能价值 6 万亿日元(420 亿美元)的交易收购供应商丰田工业公司。这将成为日本企业界一项....

专题:上海论坛2025全国股票配资公司排名出炉 来源:新闻晨报 “上海论坛2025”年会今天在上海启幕。本届论坛以“创新的时代:科技、发展、治理”为主题全国股票....

中新网嘉兴5月11日电(胡丰盛陈建钟)每年生产超过7亿件羊毛衫销往全世界20多个国家和地区;全国的毛衫产品中,平均每3件就有1件是在浙江桐乡濮院生产制造。那么,....

杭州网上配资 直播吧08月13日讯足协裁判评议:津门虎进球被吹VAR介入错误,应判进球有效! 判例一:中超联赛第20轮,天津津门虎VS青岛西海岸,比赛第35分钟....

(原标题:涛涛车业(301345.SZ):公司非美市场的销售总体呈现增长趋势)实盘配资平台 格隆汇6月11日丨涛涛车业(301345.SZ)于近期投资者关系活动....

易配牛牛是一家专业的股票配资服务平台,致力于为广大投资者提供便捷、安全、高效的配资炒股解决方案。通过易配牛牛,用户可以快速完成配资开户,获得充足的资金支持,抓住股市投资机会。平台拥有透明的操作流程、灵活的配资方案以及专业的风控体系,帮助客户降低投资风险,提升盈利能力。无论是新手还是资深投资者,易配牛牛都是您值得信赖的配资伙伴。
